Acceleration of Machine Learning Pipeline Using Parallel Computing
Introduction
In his master’s thesis work, Xavante Erickson shows how to speed up a machine learning pipeline used by a university psychology department more than 200 times. The original code was written in Matlab, and in this work, Xavante converted it to Python and implemented it on both a cloud, using the package Ray, and on a single server using Exax.
The original program took two days, or 48 hours to run. Using 25 cloud machines and Ray, the execution time is down to 15-16 minutes. On a single server using Exax, the same computation completes in only 12 minutes. Furthermore, using Exax, the computation is separated into a set of consecutive jobs, and for most experiments, only the last job has to be re-executed. This job takes only six minutes. A development iteration time of six minutes opens up for a completely different way of working compared to waiting 48 hours for each result. It is also 2.5 times faster than the cloud solution.
original: 48 HOURS
Ray: 15 minutes on 25 cloud machines
Exax: 12 minutes on single machine
Exax: 6 minutes design iteration time on single machine
The 25 cloud machines running Ray were four core Intel machines running at 2.6GHz, while the server used for the Exax tests was a 32 core EPYC machine at 3.35GHz. These setups are very different. The EPYC is faster, but limited to 32 cores. The cloud CPUs are slower, but there are 4x25=100, i.e. three times as many of them. A single machine is clearly much much cheaper, consumes much less energy, and requires significantly less effort to maintain.
The report presents a number of insights and ideas on how to speed up machine learning algorithms using Python.
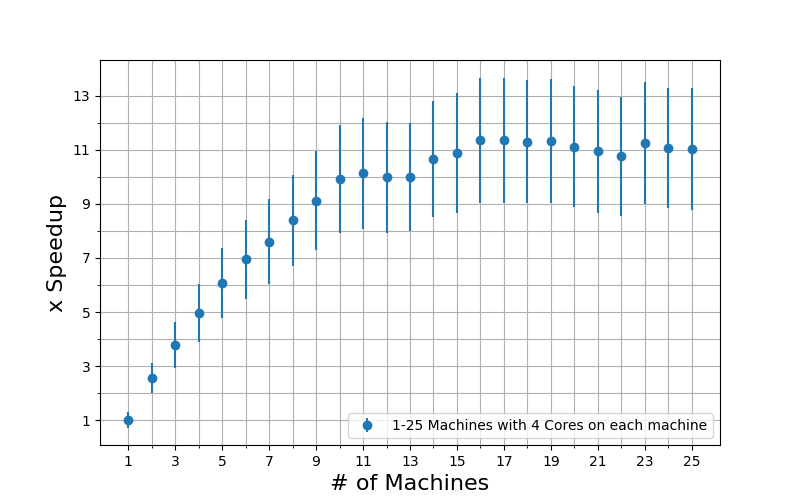
Figure: The speedup of the Ray implementation with a ninety five per- cent confidence interval when using one to twenty five machines with 4 VCPUs/Cores, relative to using one machine.
5X Faster by Disabling BLAS Internal Parallelisation!
One interesting finding is that BLAS the way it is compiled into the
Numpy PyPI package is doing parallelisation under the hood. For this
application, this does not work well. Disabling it, using
OMP_NUM_THREADS=1,1,1, makes the code executes more than 5 times
faster compared to the default setup. In raw numbers, disabling BLAS
parallelisation reduces execution speed from one hour to only 12
minutes!
Additional Resources
The Accelerator’s Homepage (exax.org)
The Accelerator on Github/exaxorg
The Accelerator on PyPI
Reference Manual